Reinforcement learning
SARSA
Computer science is filled with all sort of futuristic weird names and terms isn't it?. Only if Shakespeare had been alive he might have penned another Sonnet 116 between SARSA and Tabula Rasa:)
Sarsa is a model-free, gradient-free, on-policy, Value-based technique designed to teach a machine learning model a new Markov decision process policy in order to solve reinforcement learning challenges.
Let's take a look back,no not at Shakespeare's sonnets, but a primer on machine learning especially reinforcement learning.
Reinforcement learning algorithms are designed to teach a machine learning model a new Markov decision process policy in order to solve reinforcement learning challenges.
A Markov decision process (MDP) is a mathematical framework used to model decision-making in situations where outcomes are partly random and partly under the control of a decision-maker.
In reinforcement learning, an agent interacts with an environment, making decisions (actions) and receiving feedback (rewards) in the form of a sequence of states, actions, and rewards.
The goal of reinforcement learning is to train an agent to learn an optimal policy, which specifies the best action to take in each state to maximize cumulative rewards over time.
To achieve this, reinforcement learning algorithms, such as Q-learning, SARSA, and Expected SARSA, are employed.
These algorithms update the agent's policy based on observed rewards and transitions between states, gradually improving the agent's decision-making capabilities. By iteratively learning from experience, the agent can develop strategies to navigate complex environments and achieve desired goals.
Reinforcement learning is widely used in various domains, including robotics, gaming, finance, healthcare, and more, where agents need to learn to make decisions in dynamic and uncertain environments.
In reinforcement learning algorithms, the policy followed by the
learning agent can be categorized into two types:
On-Policy: In this approach, the learning agent updates its value
function based on the actions it selects according to the current policy
it's following. Essentially, the agent learns from its own actions based
on the policy it's currently using.
Off-Policy: In contrast, the off-policy method involves the learning
agent updating its value function based on actions derived from another
policy. This means that the agent learns by observing and evaluating
actions taken by a different policy, rather than solely relying on its
own actions.
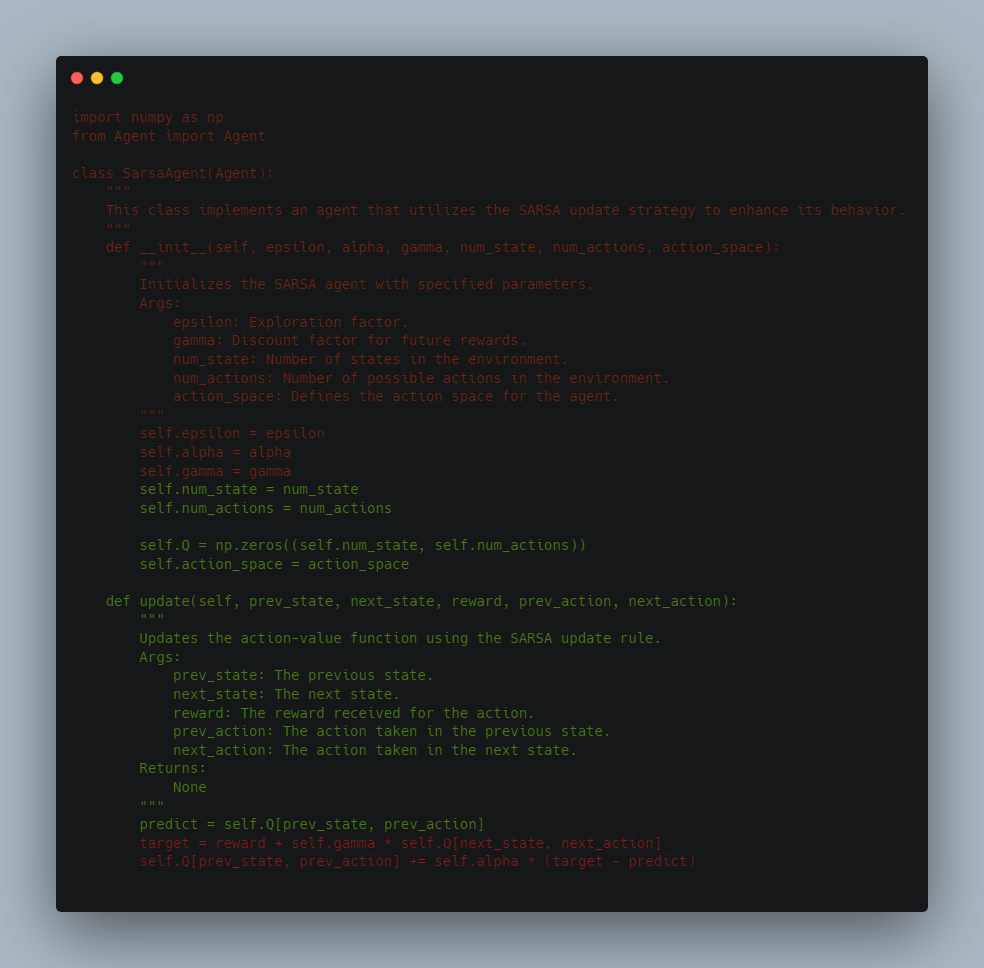
Q(St, At) = Q(St, At) + α[Rt+1 + γQ(St+1, At+1) - Q(St, At)]
In the SARSA algorithm, the Q-value undergoes updates based on the
action \( A_1 \) executed in state \( S_1 \). In contrast, Q-learning
utilizes the action with the highest Q-value in the subsequent state \(
S_1 \) for updating the Q-table. SARSA operates by executing actions
dependent on rewards obtained from prior actions.
To facilitate this,
SARSA maintains a table known as the Q-table, which contains
state-action estimate pairs, denoted as \( Q(S, A) \). The SARSA
procedure begins with the initialization of \( Q(S, A) \) to arbitrary
values. During this phase, the initial current state \( S \) is
established, and an initial action \( A \) is chosen utilizing an
epsilon-greedy algorithm.
This policy aims to balance exploitation and exploration, where
exploitation utilizes existing estimated values to maximize rewards,
while exploration seeks new actions to potentially optimize long-term
rewards. Following this initialization, the chosen action is executed,
and the ensuing reward \( R \) and subsequent state \( S_1 \) are
observed. Subsequently, \( Q(S, A) \) is updated, and the subsequent
action \( A_1 \) is determined based on the revised Q-values. The
estimates of action values for a state are also adjusted for each
existing action-state pair, reflecting the anticipated reward for
undertaking a specific action.
These steps, from \( R \) to \( A_1 \),
iteratively recur until the conclusion of the episode, delineating the
sequence of states, actions, and rewards until reaching the terminal
state. The experiences involving state, action, and reward within the
SARSA framework contribute to the continuous updating of \( Q(S, A) \)
values throughout the iterations.
The steps involved in the SARSA algorithm are
1. Initialize the action-value estimates Q(s, a) to arbitrary values.
2. Set the initial state s.
3. Choose the initial action a using an epsilon-greedy policy based on the current Q values.
4. Take action a and observe the reward r and the next state s'.
5. Choose the next action a' using an epsilon-greedy policy based on the updated Q values.
6. Update the action-value estimate for the current state-action pair using the SARSA update rule:
Q(s, a) = Q(s, a) + alpha * (r + gamma * Q(s', a') - Q(s, a))
where alpha is the learning rate, gamma is the discount factor, and r + gamma * Q(s', a') is the estimated return for the next state-action pair.
7. Set the current state s to the next state s', and the current action a to the next action a'.
8. Repeat steps 4-7 until the episode ends.
Here are some notable applications OF SARSA:
1. Robotics
In robotics, SARSA is applied for tasks such as path planning, navigation, and manipulation. Robots equipped with SARSA algorithms can learn from experience to perform complex actions in dynamic environments, adapting their behavior based on rewards received.
2. Gaming
SARSA has extensive applications in gaming, especially in developing intelligent agents for playing video games. By learning from interactions with game environments, agents trained with SARSA can optimize their decision-making processes to achieve desired outcomes, such as winning a game or maximizing rewards.
3. Trading
Financial applications of SARSA include algorithmic trading, portfolio management, and risk assessment. By modeling market dynamics as a Markov decision process, SARSA algorithms can learn to make optimal trading decisions based on historical data and real-time market conditions.
4. Healthcare
In healthcare, SARSA is used for patient treatment optimization, medical diagnosis, and personalized medicine. By analyzing patient data and treatment outcomes, SARSA algorithms can assist healthcare professionals in making informed decisions to improve patient outcomes and optimize resource allocation.
5. Autonomous Vehicles
SARSA plays a crucial role in the development of autonomous vehicles by enabling them to learn driving policies through interactions with road environments. Autonomous vehicles equipped with SARSA algorithms can adapt their driving behavior to navigate safely and efficiently in diverse traffic scenarios.